共分散構造分析について、基本的なしくみの解説、実際に各モデルについてRを用いて実行、解釈方法について解説します。
1 共分散構造分析(解説)
1.1 共分散構造分析とは
1.2 分散、共分散、相関
1.3 パス解析と係数
1.4 モデルの考え方と作成
1-5 適合度指標
CFI、TLI、RMSEA、SRMR、情報量基準(AIC、BIC)
2 共分散構造分析(実施)
2.1 分析コードの実行
2.2 モデル
・逐次モデル (Recursive Model)
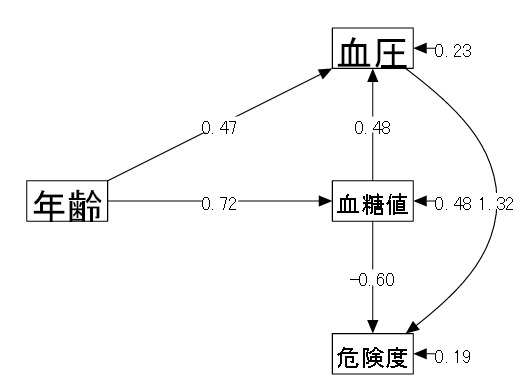
| (1) データ概要 | ある会社の健康診断を受けた男性10名の結果(仮想データ) |
| (2) 変数 | ①年齢 ②血糖値(空腹時) ③血圧(最高値) ④危険度(医者による診断、5段階評価) |
| (3) モデル | 以下のようなモデルを考える。 |
| 「④危険度 ← ②血糖値 + ③血圧」 慢性的な高血糖と高血圧により動脈硬化リスクが高まると考えられる。 | |
| 「②血糖値 ← ①年齢 ③血圧 ← ①年齢」 血糖値、血圧共に加齢による影響を受ける。 | |
| 「③血圧 ← ②血糖値」 高血糖は血液がドロドロなので血圧に影響する。 |
・非逐次モデル (non-Recursive Model)
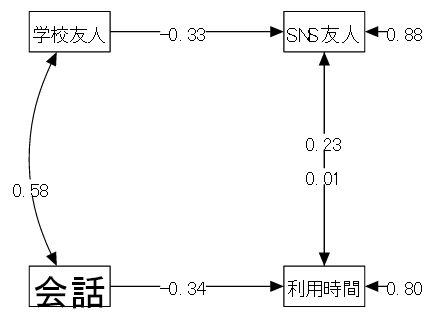
| (1) データ概要 | 高校生100名に対して以下の調査を行った(仮想データ) |
| (2) 変数 | ①利用時間(1日の平均的な利用時間:時間) ②SNS友人(SNSでつながっている友人の数) ③会話(1日の家庭での会話時間の平均:分) ④学校友人(学校で親しくしている友人の数) |
| (3) モデル | 以下のようなモデルを考える。 |
| 「①利用時間 ← ②SNS友人 + ③会話」 スマホ利用時間はネット上での交友関係と家庭での家族との会話の影響を受ける | |
| 「②SNS友人 ← ①利用時間 + ④学校友人」 ネット上の友人は、ネット利用時間と実生活での交友関係の影響を受ける |
・重回帰分析
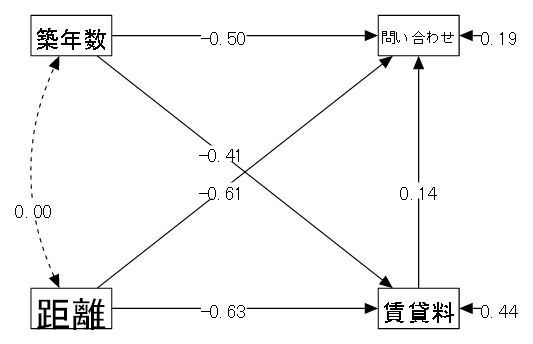
| (1) データ概要 | ある駅を最寄り駅とするアパート(間取りはほぼ同じ条件) の各種条件と問い合わせ件数(仮想データ) |
| (2) 変数 | ①賃貸料(月の賃貸料、万円) ②距離(駅からの徒歩による所要時間、分) ③築年数(年) ④問い合わせ(最近1カ月の問い合わせ件数) |
| (3) モデル | 以下のようなモデルを考える。 この例では賃貸料と問い合わせが従属変数となっているため、重回帰分析に該当する。 |
| 「①賃貸料 ← ②距離 + ③築年数」 駅からの距離と築年数によって賃貸料は変わってくる。 | |
| 「④問い合わせ ← ①賃貸料 + ②距離 + ③築年数」 問い合わせの多さは、賃貸料と駅からの距離と築年数 | |
| ②距離と③築年数は関係ないので無相関を仮定する。 |
・MIMIC (Multiple Indicator Multiple Cause)
| (1) データ概要 | 中学生25名を対象に以下の調査をした(仮想データ) |
| (2) 変数 | ①読書量(最近1ケ月の間に読んだ本の冊数) ②新聞を読む頻度(1日に新聞を読む平均時間) ③雑誌を読む頻度(1日に雑誌を読む平均時間) ④国語の成績 ⑤数学の成績 ⑥英語の成績 |
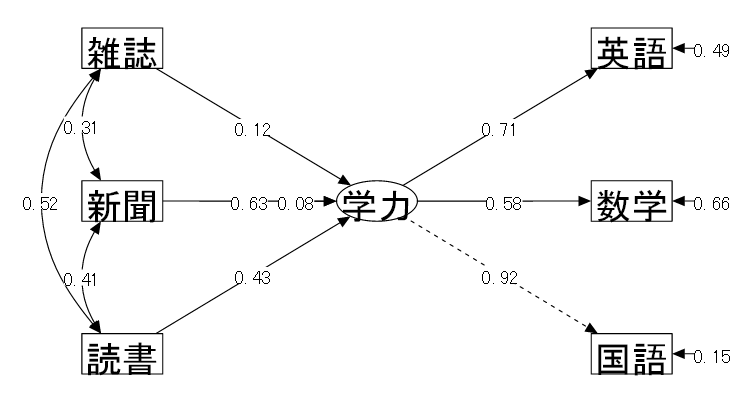
| (3) モデル | 3科目の成績から⑦学力という潜在変数を仮定し、3種の活字にふれる頻度が学力に与える影響を確認するようなモデルを立てて検証を行う。 |
| 「⑦学力 = ④国語 + ⑤数学 + ⑥英語」 各科目の成績から潜在変数としての学力が仮定される | |
| 「⑦学力 ← ①読書量 + ②新聞 + ③雑誌」 学力はそれぞれの活字にふれる頻度の影響を受ける |
・PLS (Partial Least Squares)
| (1) データ概要 | 中学生25名を対象に以下の調査をした(仮想データ) |
| (2) 変数 | ①読書量(最近1ケ月の間に読んだ本の冊数) ②新聞を読む頻度(1日に新聞を読む平均時間) ③雑誌を読む頻度(1日に雑誌を読む平均時間) ④国語の成績 ⑤数学の成績 ⑥英語の成績 |
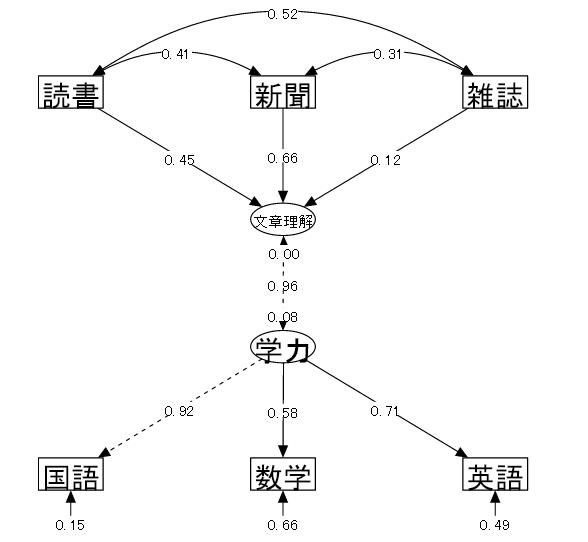
| (3) モデル | MIMICの時は潜在変数を「学力」1つとし、その分析結果から仮定された「学力」は文章に関する能力と関連性が強いと想定された。 そこで、もう1つ“学力”と活字にふれる頻度の間に⑧文章理解力という潜在変数を想定し、 3科目の成績から⑦学力という潜在変数を仮定し、3種の活字にふれる頻度が学力に与える影響を確認するようなモデルを立てて検証を行う。 |
| 「⑦学力 = ④国語 + ⑤数学 + ⑥英語」 各科目の成績から潜在変数としての「学力」が仮定される | |
| 「⑧文章理解力 = ⑦学力」 「文章理解力」は「学力」と関係がある | |
| 「⑧文章理解力 ← ①読書量 + ②新聞 + ③雑誌」 「文章理解力」はそれぞれの活字にふれる頻度の影響を受ける | |
| ⑧文章理解力の分散を0に指定する。 | |
| 「文章理解力」は矢印を受ける従属変数ではあるが、もう1つの潜在変数である「学力」とは異なる変数であり、モデル上では、3つの活字にふれる頻度の変数のみから表現されるものとして扱う。 |
・二次因子分析
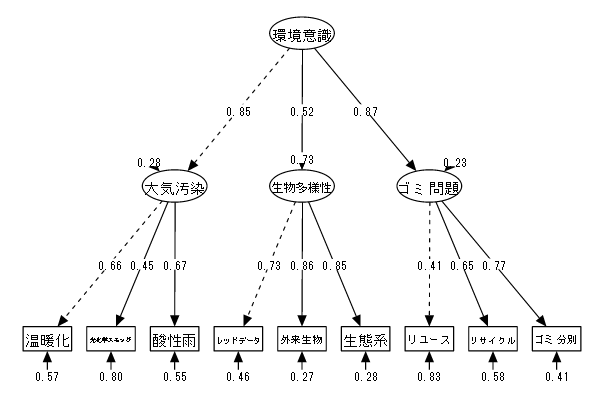
| (1) データ概要 | 100名を対象に以下の項目についての知識度を測定、7段階で評価した(仮想データ) |
| (2) 変数 | ①温暖化 ②光化学スモッグ ③酸性雨 ④レッドデータ ⑤特定外来生物 ⑥生態系 ⑦リユース ⑧リサイクル ⑨ゴミ分別 |
| (3) モデル | 大気汚染、生物多様性、ゴミの3つの問題に対する意識の高さを潜在変数として仮定し、 この3潜在変数から更に2次的な潜在変数として環境問題への意識を仮定する。 |
| 「⑩大気汚染 = ①温暖化 + ②光化学スモッグ + ③酸性雨」 「⑪生物多様性 = ④レッドデータ + ⑤特定外来生物 + ⑥生態系」 「⑫ゴミ問題 = ⑦リユース + ⑧リサイクル + ⑨ゴミ分別」 「⑬環境意識 = ⑩大気汚染 + ⑪生物多様性 + ⑫ゴミ問題」 |